Automated testing is an integral part of any major software project as a means for improving quality, productivity and flexibility. As such, it’s vital that system architecture is designed in a way to facilitate the development and execution of automated tests.
Quality is improved because automated testing execution allows us to find and solve problems early in the development cycle, much before a product change is deployed to production and becomes available to end-users.
Productivity increases because the earlier a problem is found in the development cycle, the cheaper it’s to fix it, and it’s easy to see why. If a software developer is able to run an automated test suite before integrating his code changes to the main repository he can quickly discover newly introduced bugs and fix them in the act. However, if such test suite is not available, newly introduced bugs may only appear in a manual testing phase later on, or even worse, reported by end-users, requiring developers to step out of the regular development workflow for investigating and fixing them.
Flexibility is improved because developers feel more confident for refactoring code, upgrading packages and modifying system behavior when required as they rely on a test suite with high level of coverage for assessing the impacts of their code changes.
When discussing automated testing I also like to bring up the topic of risk management to the conversation. As a lead software engineer risk management is a big part of my job, and it involves mentoring the development team in practices and processes that reduce the risks of technical deterioration of the product. From the benefits listed above it’s clear that the employment of an adequate automated testing strategy fits right in, helping to mitigate risks in a software project.
Moving forward, we can divide automated tests into at least three different types according to the strategy for implementing and running them, which are shown in the famous test pyramid below:
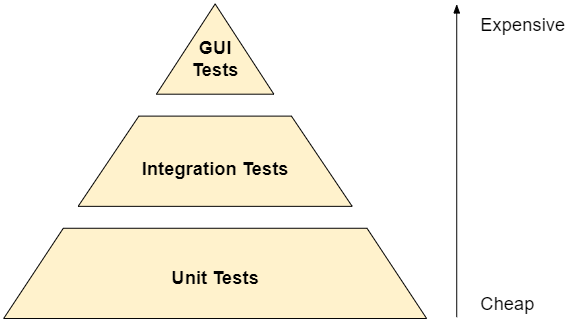
Unit tests are cheap to develop and cheap to run with respect to time and resources employed, and are focused on testing individual system components (eg: business logic) isolated from external dependencies.
Integration tests take one step further, and are developed and ran without isolating external dependencies. In this case we are interested in evaluating that all system components interact as expected when put together and faced with integration constraints (eg: networking, storage, processing, etc).
Finally, on the top of the pyramid, GUI tests are the most expensive to automate and execute. They usually rely on UI input/output scripting and playback tools for mimicking an end-user’s interaction with the system’s graphical user interface.
In this article we will be focusing on the foundation of the test pyramid, the unit tests, and on system architecture considerations for promoting their adoption.
Properties of an effective unit test
Fist, let’s enumerate what constitutes an effective, well-crafted unit test. Below is a proposition:
- Short, having a single purpose
- Simple, clear setup and tear down
- Fast, executes in a fraction of a second
- Standardized, follows strict conventions
Ideally a unit test should display all of these properties, below I elaborate why.
If the unit test isn’t short enough it will be harder to read it and understand its purpose, i.e., exactly what it’s testing. So for that reason unit tests should have a clear objective and evaluate one thing only, instead of trying to perform multiple evaluations at the same time. This way, when a unit test breaks, a developer will more easily and quickly assess the situation and fix it.
If unit tests require a lot of effort to setup their test context, and tear it down afterwards, developers will often start questioning whether the time being invested in writing these tests is worth it. Therefore, we need to provide an enviroment for writing unit tests that takes care of managing all the complexity of the test context, such as injecting dependencies, preloading data, clearing up caches, and so forth. The easier it is to write unit tests, the more motivated developers will be for creating them!
If executing a suite of unit tests takes a lot of time, developers will naturally execute it less often. The danger here lies in having such a lengthy unit test suite that it becomes impractical, and developers start skipping running it, or running it selectively, reducing its effectiveness.
Lastly, if tests aren’t standardized, before too long your test suite will start looking like the wild west, with different and sometimes conflicting coding styles being used for writing unit tests. Hence, pursuing system design coherence is as much as valid in the scope of unit testing as it is for the overall system.
Once we agree on what constitutes effective unit tests we can start defining system architecture guidelines that promote their properties, as described in the following sections.
Software complexity
Software complexity arises, among other factors, from the growing number of interactions between components within a system, and the evolution of their internal states. As complexity gets higher the risk of unintentionally interfering in intricated webs of components interactions increases, potentially leading to the introduction of defects when making code changes.
Furthermore, it’s common sense that the higher the complexity of a system, the harder it is to maintain and test it, which leads to a first (general) guideline:
Keep an eye for software complexity and follow design practices to contain it
A practice worth mentioning for managing complexity while improving testability is to employ Pure Functions and Immutability whenever possible in your system design. A pure function is a function that has the following properties:1
- Its return value is the same for the same arguments (no variation with local static variables, non-local variables, mutable reference arguments or input streams from I/O devices).
- Its evaluation has no side effects (no mutation of local static variables, non-local variables, mutable reference arguments or I/O streams).
From its properties it’s clear that pure functions are well suited to unit testing. Their usage also removes the need for much of the complementary practices which are discussed in the following sections for handling, mostly, stateful components.
Immutability plays an equally important role. An immutable object is an object whose state cannot be modified after it is created. They are more simple to interact with and more predictable, contributing for lowering the system complexity, disentangling global state.
Isolating dependencies
By their very definition unit tests are intended to test individual system components in isolation, since we don’t want the result of a component’s unit tests to be influenced by one of its dependencies. The degree of isolation varies according to specifics of the component under test and preferences of each development team. I personally don’t worry for isolating lightweight, internal business classes, since I see no value added in replacing them by a test targeted component that will display pretty much the same behavior. Be that as it may the strategy here is straightforward:
Apply the dependency inversion pattern in component design
The dependency inversion pattern (DIP) states that both high-level and low-level objects should depend on abstractions (e.g. interfaces) instead of specific concrete implementations. Once a system component is decoupled from its dependencies we can easily replace them in the context of a unit test by simplified, test targeted concrete implementations. The class diagram below illustrates the resulting structure:
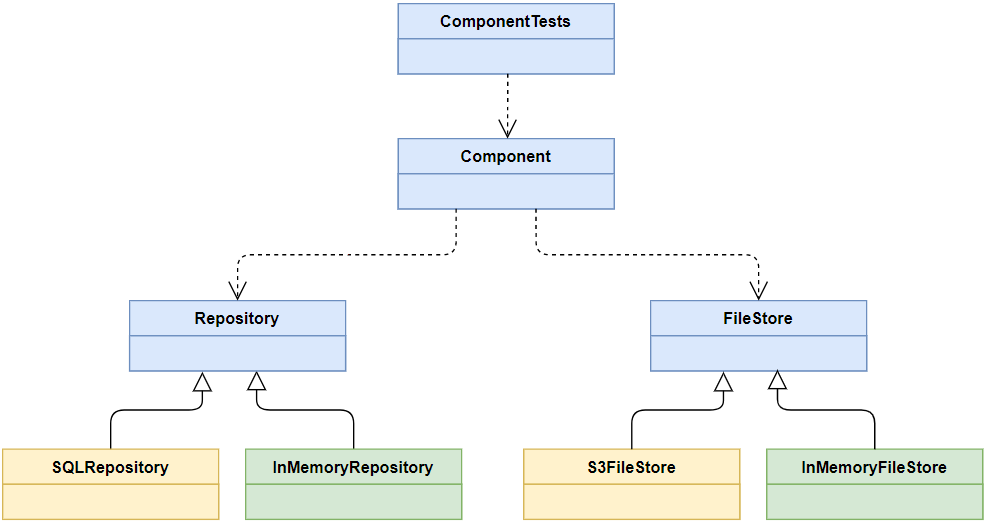
In this example the component under test is dependent on Repository and FileStore abstractions. When deployed to production we might inject a concrete SQL based implementation for the repository class and a S3 based implementation for the file store component, for storing files remotely in the AWS Cloud. Nevertheless, when running unit tests we will want to inject simplified functional implementations that don’t rely on external services, such as the “in memory” implementations painted in green.
If you’re not familiar with the DIP, I have another article that goes through a practical overview on how to use it in a similar context that you may find helpful: Integrating third-party modules.
The Mocks vs Fakes debate
Notice that I’m not referring to these “in memory” implementations as “mocks”, which are simulated objects that mimic the behavior of real objects in limited, controlled ways. I do this deliberately, since I’m against the usage of mock objects in favor of fully compliant “fake” implementations that give us more flexibility for writing unit tests, and can be reused across several unit test classes in a more reliable way than setting up mocks.
To get into more detail suppose we are writing a unit test for a component that depends on the FileStore abstraction. In this test the component adds an item to the file store but isn’t really worried whether the operation succeeds or fails (eg: a log file), and hence we decide to mock that operation in a “dummy” way. Now suppose that later on requirements change, and the component needs to ensure that the file is created by reading from the file store before proceeding, forcing us to update the mock’s behavior in order for the test to pass. Then, imagine requirements change yet again and the component needs to write to multiple files (eg: one for each log level) instead of only one, forcing another improvement of our mock object behavior. Can you see what’s happening? We are slowly improving our mock making it more similar to a concrete implementation. What’s worse is that we may end up with dozens of independent, half-baked, mock implementations scattered throughout the codebase, one for each unit test class, resulting in more maintenance effort and less cohesion within the testing environment.
To address this situation I propose the following guideline:
Rely on Fakes for implementing unit tests instead of Mocks, treating them as first class citizens, and organizing them in reusable modules
Since Fake components implement business behavior they’re inherently a more costly initial investment when compared to setting up mocks, no doubt about that. However, their return in the long-term is definitely higher, and more aligned with the properties of effective unit tests.
Coding style
Every automated test can be described as a three-step script:
- Prepare test context
- Execute key operation
- Verify outcome
It’s logical to consider that, given an initial known state, when an operation is executed, then it should produce the same expected outcome, every time. For the outcome to turn out different either the initial state has to change, or the operation implementation itself.
You’re probably familar with the words marked in bold above. If not, they represent the popular Given-When-Then pattern for writing unit tests in a way that favors readability and structure. The idea here is simple:
Define and enforce a single, standardized coding style for writing unit tests
The Given-When-Then pattern can be adopted in a variety of ways. One of them is to structure a unit test method as three distinct methods. For instance, consider a password strength test:
[TestMethod]
public void WeakPasswordStrengthTest()
{
var password = GivenAWeakPassowrd();
var score = WhenThePasswordStrengthIsEvaluated(password);
ThenTheScoreShouldIndicateAWeakPassword(score);
}
private string GivenAWeakPassowrd()
{
return "qwerty";
}
private int WhenThePasswordStrengthIsEvaluated(string password)
{
var calculator = new PasswordStrengthCalculator();
return (int)calculator.GetStrength(password);
}
private void ThenTheScoreShouldIndicateAWeakPassword(int score)
{
Assert.AreEqual((int)PasswordStrength.Weak, score);
}
Using this approach the main test method becomes a three-line description of the unit test’s purpose that even a non-developer can understand with ease just by reading it. In practice, unit tests main methods end up becoming a low level documentation of your system’s behaviour providing not only a textual description but also the possibility to execute the code, debug it and find out what happens internally. This is extremely valuable for shortening the system architecture learning curve as new developers join the team.
It is important to highlight that when it comes to coding style, there’s no single right way of doing it. The example I presented above may please some developers and displease others for, say, being verbose, and that’s all right. What really matters is coming to an agreement within your development team on a coding convention for writing unit tests that make sense to you, and stick to it.
Managing test contexts
Unit test context management is a topic that is not discussed often enough. By “test context” I mean the entire dependency injection and initial state setup required for successfully running unit tests.
As noted before unit testing is more effective when developers spend less time worrying about setting up test contexts and more time writing test cases. We derive our last guideline from the observation that a few test contexts can be shared by a much larger number of test cases:
Make use of builder classes to separate the construction of test contexts from the implementation of unit test cases
The idea is to encapsulate the construction logic of test contexts in builder classes, referencing them in unit test classes. Each context builder is then responsible for creating a specific test scenario, optionally defining methods for particularizing it.
Let’s take a look at another illustrative code example. Suppose we are developing an anti-fraud component for detecting mobile application users suspicious location changes. The test context builder might look like this:
public class MobileUserContextBuilder : ContextBuilder
{
public override void Build()
{
base.Build();
/*
The build method call above is used for
injecting dependencies and setting up generic
state common to all tests.
After it we would complete building the test
context with what's relevant for this scenario
such as emulating a mobile user account sign up.
*/
}
public User GetUser()
{
/*
Auxiliary method for returning the user entity
created for this test context.
*/
}
public void AddDevice(User user, DeviceDescriptior device)
{
/*
Auxiliary method for particularizing the test
context, in this case for linking another
mobile device to the test user's account
(deviceType, deviceOS, ipAddress, coordinates, etc)
*/
}
}
The test context created by this MobileUserContextBuilder is generic enough that any test case required to start from a state in which the application already has a mobile user registered can use it. On top of that it defines the AddDevice method for particularizing the test context to fit our fictitious anti-fraud component testing needs.
Consider that this anti-fraud component is called GeolocationScreener and is responsible for checking wether or not a mobile user’s location changed too quickly, which would indicate that he’s probably faking his real coordinates. One of its unit tests might look like the following:
public class GeolocationScreenerTests
{
[TestInitialize]
public void TestInitialize()
{
context = new MobileUserContextBuilder();
context.Build();
}
[TestMethod]
public void SuspiciousCountryChangeTest()
{
var user = GivenALocalUser();
var report = WhenTheUserCountryIsChangedAbruptly(user);
ThenAnAntiFraudAlertShouldBeRaised(report);
}
[TestCleanup]
public void TestCleanup()
{
context.Dispose();
}
private User GivenALocalUser()
{
return context.GetUser();
}
private SecurityReport WhenTheUserCountryIsChangedAbruptly(User user)
{
var device = user.CurrentDevice.Clone();
device.SetLocation(Location.GetCountry("Italy").GetCity("Rome"));
context.AddDevice(user, device);
var screener = new GeolocationScreener();
return screener.Evaluate(user);
}
private void ThenAnAntiFraudAlertShouldBeRaised(SecurityReport report)
{
Assert.AreEqual(RetportType.Geolocation, report.Type);
Assert.IsTrue(report.AlertRaised);
}
private MobileUserContextBuilder context;
}
It’s visible that the amount of code dedicated to setting up the test context in this sample test class is minimal, since it’s almost entirely contained within the builder class, preserving code readability and organization. The amortized time taken for setting up the test context becomes very short as more and more test cases take advantage of the available library of test context builders.
Conclusion
In this post I have covered the topic of unit testing providing five major guidelines for addressing the challenge of mantaining effectiveness in an ever growing base of test cases. These guidelines have important ramifications in system architecture, which should, from the begining of a software project, take unit testing requirements into account in order to promote an environment in which developers see value in and are motivated to write unit tests.
Unit tests should be regarded as a constituent part of your system architecture, as vital as the components they test, and not as second class citizens that the development team merely writes for the purpose of filling up managerial reports check boxes or feeding up metrics.
In closing, if you’re working in a legacy project with few or none unit tests, that doesn’t employ the DIP, this post may not contain the best strategy for you, since I intentionally avoided talking about sophisticated mocking frameworks that, in the context of legacy projects, become a viable option for introducing unit tests to extremely coupled code.
Notes
- I have decided to incorporate the “Software complexity” section into the article only after receiving a feedback in a reddit comment. For reference you can find the original article here.
Sources
[1] Bartosz Milewski (2013). “Basics of Haskell”. School of Haskell. FP Complete. Retrieved 2018-07-13.