Complexity is present in any project. Some have more, some have less, but it’s always there. The manner in which a team handles complexity can pave the way for a project’s success or lead towards its technical demise.
In the context of software, complexity arises from a variety of factors, such as complicated requirements, technical dependencies, large codebases, integration challenges, architectural decisions, team dynamics, among others.
When talking to non-technical folks, especially those not acquainted with the concepts of software complexity and technical debt, it can be helpful to present the topic from a more managerial perspective.
So I propose the following qualitative diagram that regards complexity as an inherent property of a software project, and simultaneously, a responsibility that a software development team must constantly watch and manage for being able to deliver value in the long run:
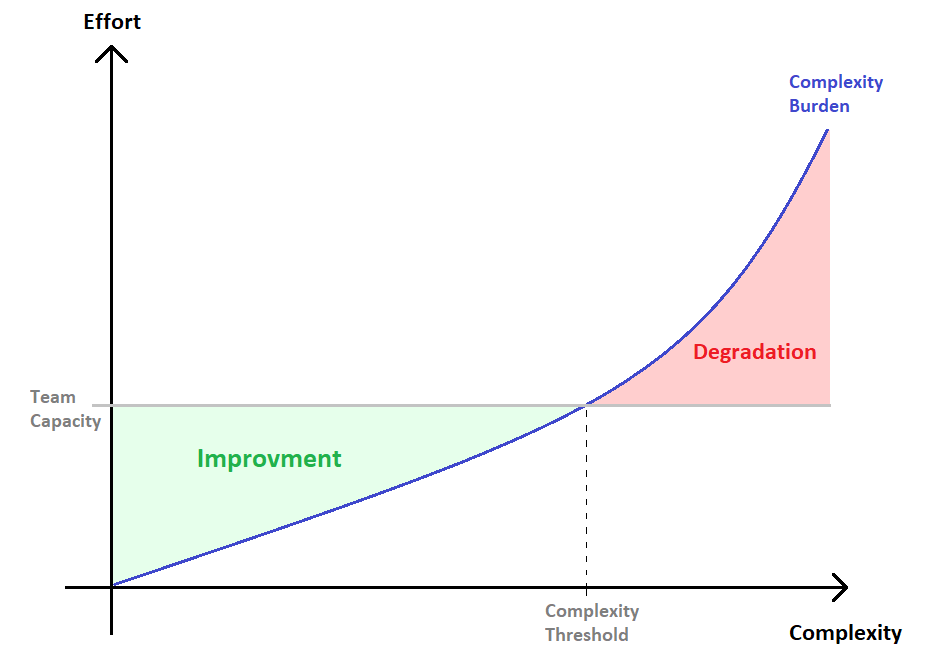
From the diagram:
-
The Complexity Burden curve represents the theoretical amount of effort necessarily spent servicing complexity, as oposed to productive work. This is an inevitable aspect of software development and can manifest in various forms, including spending time understanding and working with complex code, encountering more intricate bugs and errors, updating depencencies, struggling to onboard new team members due to excessively elaborate designs, among others.
-
The Team’s Capacity line is the maximum amount of effort the team is able to provide, which varies over time and can be influenced by factors such as changes in the product development process, team size, and efforts to eliminate toil [1]. Additionally, reductions in the complexity burden of a project can unlock productivity, influencing the team’s capacity as well.
-
The Complexity Threshold represents the point where the team’s capacity becomes equal to the complexity burden. In this theoretical situation, the team is only allocating capacity towards servicing complexity. Value delivery is compromised.
With these definitions in place, let’s review the two colored zones depicted in the diagram.
The Improvment Zone
Projects are typically in the improvement zone, which means that the team has enough capacity to handle the complexity burden and still perform productive work. The lower the complexity burden, the more efficient and productive the team will be in delivering results. The team can choose to innovate, develop new features, optimize performance, and improve UX. It’s worth noting that doing so may result in added complexity. This is acceptable as long as there is sufficient capacity to deal with the added complexity in the next cycles of development and the team remains continuously committed to addressing technical debt.
The Degradation Zone
A project enters the degradation zone when the team's capacity is insufficient for adequately servicing complexity, adding pressure on an already strangled project. The team will constantly be putting out fires, new features will take longer to ship, bugs will be more likely to be introduced, developers may suggest rewriting the application, availability may be impaired, and customers may not be satisfied. The viable ways out of this situation are to significantly reduce complexity or to increase capacity. Other efforts will be mostly fruitless.
Closing thoughts
The concept of complexity burden can be a valuable tool for enriching discussions around promoting long-term value delivery and preventing a project from becoming bogged down by complexity, leaving little room for new feature development. It’s important to make decisions with a clear understanding of the complexity burden and how it may be affected.
It’s worth pointing out that if the productive capacity of a team is narrow, meaning if the proportion of the team’s capacity allocated towards the complexity burden is already too high, the team will find itself in a situation where continuing to innovate may be too risky. The wise decision then will be to prioritize paying off technical debt and investing in tasks to alleviate the complexity burden.
Even though they are related, it’s crucial to distinguish between the complexity burden and technical debt. The former materializes as the amount of (mostly) non-productive work a team is encumbered by, while the latter is a liability that arises from design or implementation choices that prioritize short-term gains over long-term sustainability [2]. A project can become highly complex even with low technical debt.
Finally, a project is a dynamic endeavor, and a team may find itself momentarily in the “degradation” zone in one cycle and in the “improvement” zone in the next. What matters most is to be aware of the technical context and plan next steps preemptively, aiming to maintain the complexity burden at a healty level.
Reference
[1] Google - Site Reliability Engineering. Chapter 5 - Eliminating Toil