The deployment is arguably the most critical software development life cycle (SDLC) phase. It takes an application from a battle tested generally stable version to a newer version which introduces new features, improvements and bug fixes. As much as we employ automated tests and set up a staging environment for quality assurance (QA), covering all use cases before deploying to production to make sure an application version is free of defects is unfeasible. Hence, a successful deployment model needs to handle not only software release, but also application monitoring and restoration.
The following sections discusses the deployment process in more detail, proposing a handful of rules for successfully managing risks associated with this process.
Deployable Image
In this context the deployable image is an executable package built from the application’s source code for distribution to test, staging and production environments. Two common formats are:
- Container image: includes the application’s binaries built from source code, the runtime, system tools, system libraries and settings, everything required for running the application in a virtualization platform.
- Binary package: includes only the application’s binaries built from source code, usually targeting a pre-determined hosting platform, such as a pre-configured virtual machine running a specific OS version.
Generating the deployable image is the first step of deployment, and as a first rule, you should:
Use the same deployable image for test, staging and production environments
This means that whenever a problem is detected and a code fix is required, the newly generated deployable image validation should start back at the test environment before moving forward through the pipeline. This helps reduce the degree of uncertainty in the deployable image as it goes through each environment, since even rebuilding an application from source code can introduce behavior changes due to different build machine configuration, or accidental package dependencies updates.
System Downtime
From the application user’s perspective deployment should happen seamlessly, without any sudden interruptions or problems. Any amount of downtime can result in loss of confidence in the application and even lead to financial implications. With this in mind, as a second rule, you should:
Update systems without downtime
If you’re adopting container images in your deployment process this becomes a lot easier, since it’s possible to allocate application services containers without much effort, having the new version and old version available side by side, and then switch networking traffic to the new version:
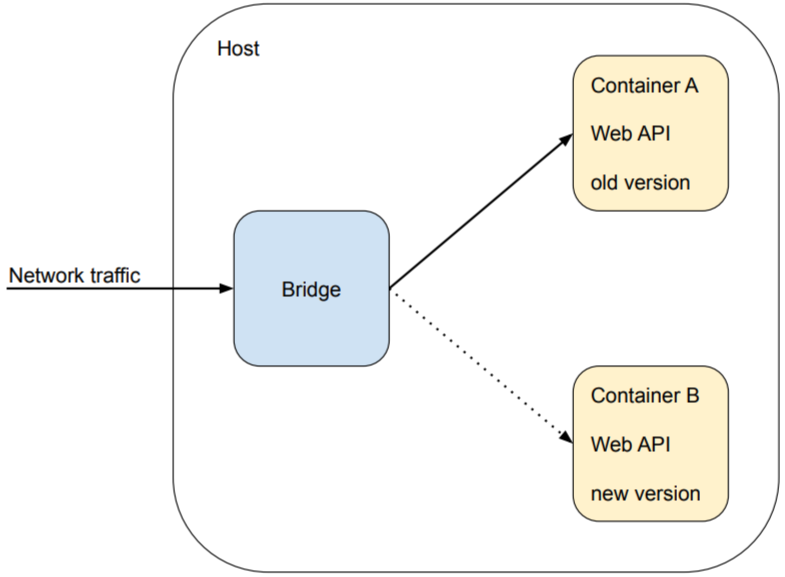
From here there are two approaches:
- Hard switch: You simply flip the switch, disconnecting the old version from the network and exposing the entirety of your users to the new version.
- Canary release: A small set of users is initially exposed to the new version (ex: 5%), and as you become more confident that this version is stable, you gradually increase the percentage of users routed to the new version until reaching 100%.
Canary release is better for mitigating deployment risks, but usually requires more work to set up. Either way, once the new version container is online and healthy, the old version container can be safely removed from the host.
Automated Execution
We humans are prone to error. The more a deployment process rely on manual steps, the riskier it gets. A simple honest mistake in one manual step can be sufficient to bring your application down. For instance, someone could mistakenly apply staging configuration to the production environment, or inadvertently revert the order in which dependable services are deployed, causing them to crash.
Therefore, as a third rule, you should:
Fully automate the deployment process
It shouldn’t take you more than one click to deploy your application. More sophisticated applications even employ continuous deployment, in which a single commit to the main repository’s master branch is enough to trigger an automated deployment to production. However, these applications rely deeply on automation for testing, canary releasing and monitoring.
Monitoring
The main goal of monitoring is to automatically detect problems as soon as possible when they occur, so we can fix them as quickly as possible. Ideally it should be comprehensive enough that we never feel the need to check something manually. Instead, we rely on system administrators being automatically notified when a problem is detected.
Then, as a fourth rule you should:
Set up and rely on automatic monitoring for early problem detection
There are at least two lines of monitoring which are effective for closing the feedback loop in the deployment process: health monitoring and error monitoring.
Health Monitoring
In this line of monitoring we are interested in assuring that our application is performing as expected. First we define a set of system and business metrics that adequately represents the application behaviors. Then we start tracking these metrics, triggering an alert whenever one of them falls outside of its expected operational range.
A few examples of system metrics are:
- Number of active database connections
- Web server requests per second
- Available memory per host machine
- IOPS per host machine
As for business metrics, a few examples are:
- User registration rate
- Number of online users
- Image upload rate (for media sharing application)
- Content like rate (for a social application)
Error Monitoring
Errors are continuously occurring in applications, but most of them are known and expected errors, such as authentication token expiration errors, or database query timeout errors. In this line of monitoring we are interested in discovering deviations, or anomalies, from the expected occurrence of application errors, triggering an alert when that happens. An anomaly can be identified as:
- A significant and unexpected increase (or decrease) in the rate of a known error
- A consistent manifestation of a new, unexpected, type of error
Monitoring is valuable not only during deployment, but also long after it’s been completed. The faster we are able to identify and solve issues, the less users will be negatively affected by them.
Reversibility
Sooner or later, no matter what, deployment problems will happen, it’s a fact, and if you’re not prepared to handle them quickly, then you’re taking high risks in doing so, depending on good odds favoring you.
As we’ve learned in the previous section monitoring should give us enough information to detect and evaluate problems as they happen. Problems can be manageable, meaning that we can act on them while they’re occurring in the production environment, or they can be showstoppers, meaning that we will need to solve them immediately, bringing the production environment back to a stable state.
Fortunately there’s a straightforward way for dealing with the latter case: reverting the application back to its earlier, stable version. Then, as a fifth rule you should:
Support rollback to earlier application versions
From figure 1 this can be as simple as flipping the switch back to the original container for all hosts, but this only handles the case when there’s a need to revert to the immediately previous version. You’ll have to keep a deployable image rollout history for being able to execute a rollback deployment reverting your application to older versions.
There is a special case to be careful though. As the application evolves, so does the database schema and stored data. If you design the database to evolve while preserving backwards compatibility with earlier application versions, you should be fine. But sometimes this may not possible and we are required to release a version with breaking changes to the database. A strategy to handle this scenario is to incorporate migration scripts to the deployment, one for committing changes to the database, and one for reverting them.
This article is intended to provide guidelines and best practices for helping to reduce risks associated with the deployment process. It takes reasonable effort and time to achieve a matured and reliable deployment process that works for your application, so don’t feel rushed to build a full fledged process right from scratch, but commit yourself to gradually and constantly improve it.